

This guide explains how LLMs work, and it also covers the real mechanics that make them possible, from tokens and embeddings to transformers, training, inference, safety, and limitations
Large language models have quickly gone from being a niche research topic to becoming the engine behind chatbots, AI writing tools, coding assistants, enterprise search, and many of the most talked-about products in technology.
They feel impressive because they can respond in natural language, adapt to many tasks, and often produce answers that sound thoughtful, organized, and surprisingly human.
So, without any further ado, let’s learn everything about “How LLMs Work.”
Key Takeaways
- LLMs work by turning text into tokens, converting those tokens into embeddings, and processing them through transformers with self-attention.
- They generate responses one token at a time, which is why inference is sequential and different from training.
- Their capabilities come from large-scale pretraining, then fine-tuning and alignment to make them more useful and safer.
- They are powerful, but they can still hallucinate, reflect bias, and require large amounts of compute.
- The best way to use LLMs is to pair them with retrieval, verification, and human judgment.
What is an LLM?
A large language model, or LLM, is a type of AI model trained on massive amounts of text so it can understand prompts and generate language in a way that resembles human writing.
It is called a language model because its central task is to model language, which means learning how words, phrases, facts, and patterns tend to appear together in real-world text.
It is called large because modern systems are trained on enormous datasets and contain huge numbers of parameters, which are the internal values adjusted during learning.
Those parameters are not little fact cards stored neatly in memory. They are learned weights spread across the network, and together they help the model recognize patterns and make predictions.
A simple way to think about an LLM is to imagine a system that has read an extraordinary amount of text and become very good at continuing it in useful ways.
That is why the same model can answer questions, summarize long documents, rewrite awkward sentences, generate code, brainstorm ideas, and explain technical concepts.
How do LLMs work?
When you type a prompt into an LLM-powered system, the process begins with tokenization, where your text is broken into tokens the model can process numerically.
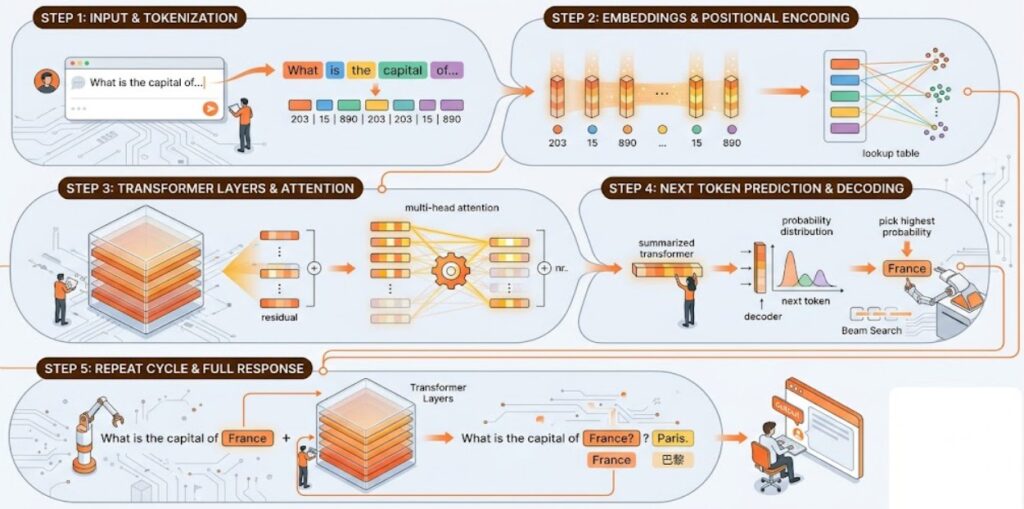
Those tokens are converted into embeddings, enriched with positional information, and passed through layers of transformer computation that use attention to determine which parts of the context matter most.
The model then predicts the next token, chooses one using a decoding strategy, appends it to the sequence, and repeats that cycle until a full response is produced.
Behind that apparently simple interaction sits a huge stack of training, optimization, alignment, and safety work that turns pattern prediction into something useful enough for real products.
That is the real story of how LLMs work. They are not magic, and they are not minds in the human sense.
They are large predictive systems built on transformer architecture, trained at scale, shaped by post-training, and deployed through carefully engineered products.
Once you understand that pipeline, the mystery drops away. You can see why these systems are powerful, why they sometimes fail, and why they are becoming such an important part of how people search, write, code, learn, and work.
How Popular Tools Use LLMs
Tools like ChatGPT, Grok, Claude, Gemini, and many enterprise AI products are built around LLMs, but the model itself is only one part of the final experience.
These systems often include prompt formatting, moderation layers, conversation history handling, retrieval systems, tool use, and user interface design on top of the core model.
So when you ask a question in a chat app, the system is usually doing more than simply passing your raw text into a model.
It may add system instructions, retrieve external documents, filter harmful requests, and structure the conversation so the model can respond more effectively.
Tokenization: The First Step in LLM Processing
Before a model can do anything useful with your prompt, it has to break the text into tokens. This process is called tokenization, and it is the bridge between human-readable language and the numerical units a model can actually process.
Humans see a sentence as words and meaning. A model sees token IDs. So if you type a question into an AI tool, the first thing that happens is not “understanding” in the human sense.
It is tokenization, which converts the text into a structured sequence that the system can feed into the network.
Real Tokenization Example
Suppose a user writes, “How do LLMs work?” A tokenizer will split that sentence into tokens according to the model’s vocabulary, and the exact split may vary between systems
. Common words may stay whole, while less common strings may be broken into smaller pieces so they can still be represented efficiently.
This matters because the model is not literally reading “How,” “do,” and “work” the way a person does.
It is working with tokenized units, and everything that happens later depends on those units being turned into numerical form first.
Byte-Pair Encoding (BPE) Process
Many language models use a subword tokenization approach, such as byte pair encoding, often called BPE. The basic idea is to build a vocabulary of useful text fragments by repeatedly merging commonly occurring character pairs, so frequent patterns become efficient tokens while rare words can still be represented as combinations of smaller parts.
This is one reason a model can handle both common words and unusual ones without needing a separate full-word entry for everything in the language.
It also helps with slang, technical terms, typos, and new vocabulary, which appear constantly in real-world text.
Context Windows and Token Limits
LLMs do not have unlimited working memory for a conversation. They operate within a context window, which is the maximum number of tokens the model can consider at one time for the current input and output.
If the conversation grows beyond that limit, some earlier content may be truncated, summarized, or otherwise managed by the application.
This is why token counts matter so much in practice. They affect how much information the model can hold in the current exchange, how long prompts can be, how much output can be generated, and how much usage may cost in many commercial systems.
Embeddings – Transforming Tokens into Meaningful Mathematical Vectors
Once text has been tokenized, each token must be converted into a vector, which is a list of numbers that places that token in a learned mathematical space. These vectors are called embeddings, and they allow the model to represent relationships between tokens in a way computation can use.
The important idea is that embeddings are not random. During training, the model learns vector representations that help it capture patterns of meaning and usage. So tokens that appear in similar contexts often end up closer together in that space than tokens with unrelated uses.
Positional Embeddings for Word Order
Embeddings alone are not enough, because a sentence is not just a bag of words. Word order changes meaning. Models, therefore, need a way to represent where each token appears in the sequence, so they can distinguish between sentences that use the same words in different orders.
This is handled through positional information, such as positional encodings or related methods used by transformer architectures. The goal is simple: help the model understand sequence structure so it knows what came first, what came later, and how tokens relate across a passage.
How Embeddings Capture Meaning
Embeddings help because they give the model a richer starting point than raw IDs. A token is no longer just “number 4217.” It becomes a structured representation that can interact with other representations based on learned patterns of usage.
That is why embeddings are so foundational to modern language models. They help the model move from discrete symbols toward relationships, similarity, and context-sensitive interpretation.
The Transformer: The Architecture Behind Every Major LLM
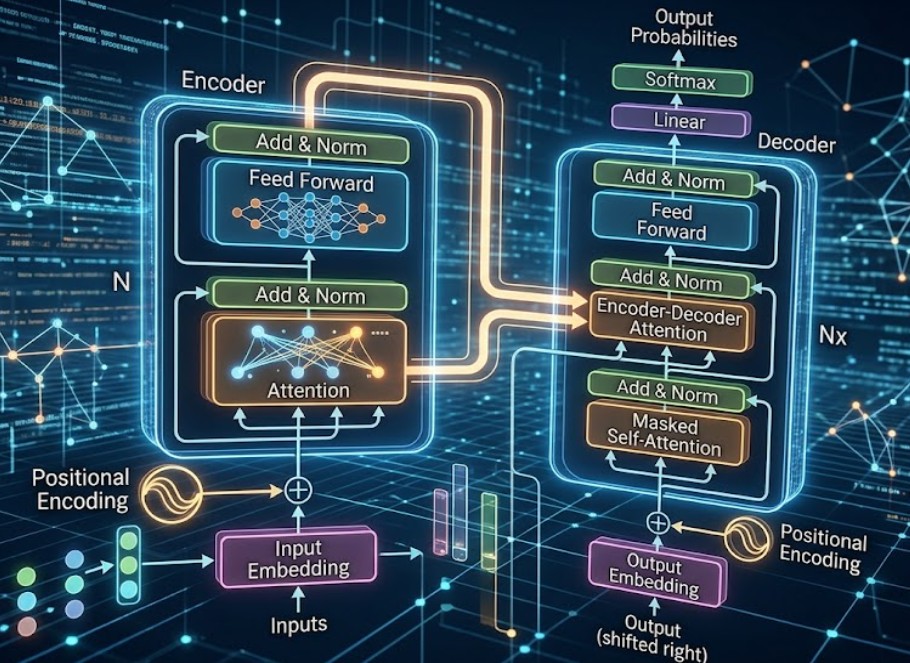
Modern LLMs are built around transformer architecture, which became dominant because it handles context and scale better than older sequence models such as recurrent neural networks.
Earlier systems processed text more sequentially and often struggled more with long-range dependencies or efficient large-scale training.
Transformers changed the game by allowing models to compare tokens across a sequence more directly through attention mechanisms. That made it easier to learn relationships across longer passages and train larger systems more effectively.
Self-Attention Mechanism (Complete Breakdown)
Self-attention is the mechanism that allows each token to consider other tokens in the same sequence and estimate which ones matter most for interpreting the current token. Instead of treating every earlier word as equally important, the model can learn to focus more strongly on the pieces of context that are most relevant.
This matters a lot for language, because meaning often depends on relationships spread across a sentence or paragraph. Pronouns, references, qualifiers, and long-distance dependencies become easier to handle when the model can actively weigh different parts of the input against one another.
Query-Key-Value (QKV)
The attention process is commonly described using queries, keys, and values. In simple terms, each token produces a query that represents what it is looking for, a key that represents what kind of information it contains, and a value that carries the actual content to be combined if there is a strong match.
The model compares queries with keys, determines how strongly tokens relate, and then blends the values accordingly. You do not need to memorize the formulas to understand the key outcome: attention lets the model decide where to focus rather than treating context as flat and uniform.
Multi-Head Attention
Transformer models do not rely on a single attention pattern. They use multi-head attention, which means several attention operations run in parallel and capture different kinds of relationships in the same text.
One head may become sensitive to local phrase structure, another to long-range reference, and another to semantic similarity, even if those roles are not perfectly neat or human-labeled. This gives the model more flexibility and expressive power than a single attention pass alone.
Feed-Forward Networks
Attention is only one part of a transformer block. After attention, the token representations are passed through feed-forward layers that further transform and refine what the model has learned from the sequence.
A useful mental model is that attention helps the model gather context, while the feed-forward layers help process and reshape that information. Repeating this pattern across many layers allows the model to develop increasingly sophisticated internal representations.
Layer Structure and Normalization
Transformer blocks are stacked repeatedly, and each block typically includes attention, feed-forward processing, normalization, and residual connections that help stabilize learning. These design choices are important because deep models are hard to train without mechanisms that preserve information flow and keep values in workable ranges.
As the input passes upward through many layers, the model keeps refining its interpretation of the sequence. That layered refinement is part of why transformer-based LLMs can move from raw text to nuanced output that feels coherent and context-aware.
Absolutely. Here is a more polished, slightly longer, premium-sounding version of that section in a tight subheading format.
How LLMs Are Trained
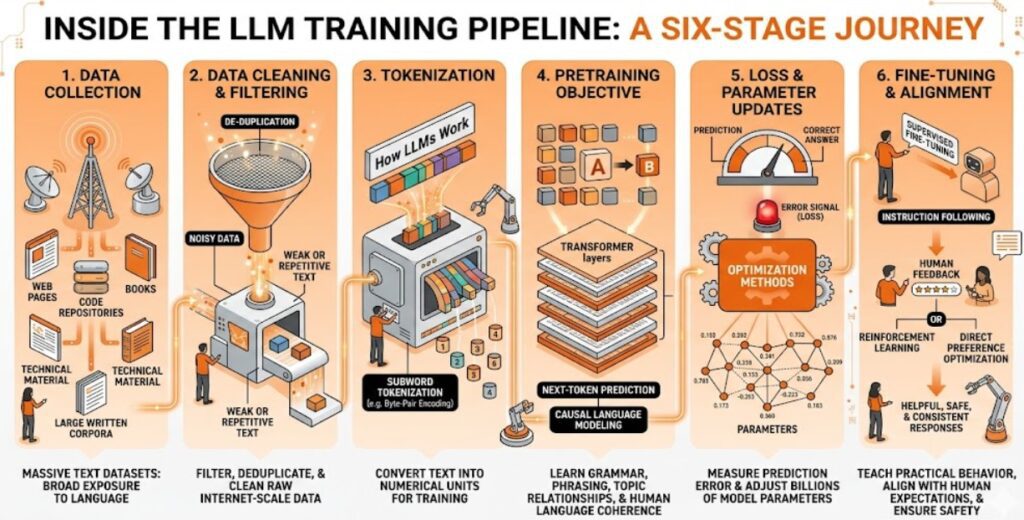
Here is how LLMs are trained.
Data Collection
Training begins with the collection of massive text datasets drawn from sources such as web pages, books, code repositories, technical material, and other large-scale written corpora, because the model needs broad exposure to real language across different domains and formats.
The goal at this stage is not just quantity, but coverage, so the model can absorb patterns from conversation, formal writing, technical explanation, and structured information alike.
Data Cleaning and Filtering
Raw internet-scale data is messy, repetitive, and often unreliable, so it is usually filtered, deduplicated, and cleaned before training starts. This stage has a major impact on model quality, because a system trained on weak or noisy text is more likely to produce weak or noisy outputs later.
Tokenization
Once the dataset is ready, the text is converted into tokens, which are the numerical units the model actually processes during training.
Many modern LLMs use subword tokenization methods such as byte pair encoding so they can handle both common vocabulary and rare or unfamiliar words without requiring a separate full-word entry for everything.
Pretraining Objective
Most generative LLMs are pretrained using next-token prediction, also known as causal language modeling, where the model sees a sequence of tokens and tries to predict the next one.
By repeating that process across enormous amounts of text, the model gradually learns grammar, phrasing, formatting patterns, topic relationships, and many of the structures that make human language coherent.
Loss and Parameter Updates
Every time the model predicts the wrong next token, the training system calculates an error signal, often called loss, that measures how far the prediction was from the correct answer.
Optimization methods then update the model’s parameters so that future predictions become more accurate over time, which is how the model slowly improves across billions of training steps.
Compute and Scaling
Training a serious LLM requires enormous computing infrastructure, because modern models are too large to train efficiently on a single machine.
Research and industry practice have shown that performance tends to improve as data, model size, and compute scale together, which is why scaling has been such a central idea in the development of modern language models.
Fine-Tuning and Alignment

Pretraining gives the model broad language ability, but it does not automatically make it a useful assistant, so developers typically apply supervised fine-tuning to teach better instruction following and more practical response behavior.
Many systems also go through alignment stages, including preference-based methods such as reinforcement learning from human feedback or direct preference optimization, to make outputs more helpful, safer, and more consistent with user expectations.
RAG, Chain-of-Thought, MoE, and Long Context Innovations
Retrieval-Augmented Generation (RAG)
Retrieval-augmented generation, or RAG, combines an LLM with an external retrieval system that fetches relevant documents and feeds them into the prompt.
This helps the model answer with fresher or more domain-specific information instead of relying only on what it absorbed during training.
RAG is especially useful in enterprise settings where the goal is not just to sound fluent, but to answer from a trusted body of documents such as policies, product manuals, research papers, or internal knowledge bases.
Chain-of-Thought Prompting
Chain-of-thought prompting encourages the model to produce intermediate reasoning steps rather than only a final answer.
This can improve performance on some tasks, especially those involving arithmetic, multi-step logic, or structured problem solving.
The main idea is simple: when the model is prompted to unpack the path to an answer, it sometimes performs better than when it is pushed to jump straight to the result.
That does not mean every visible reasoning trace is reliable, but it does show that prompting style can influence performance meaningfully.
Mixture of Experts (MoE)
Mixture of experts is an architectural approach in which different parts of the model specialize, and only selected experts are activated for a given token or input.
This can make it possible to build systems with high overall capacity while controlling computation more efficiently than a fully dense model of the same effective size.
The rough intuition is that not every token needs every part of the network equally. Routing lets the model use a more selective path, which can help with scaling and efficiency.
Long Context Handling
Long-context work aims to help models handle much larger sequences effectively, whether that means longer documents, longer conversations, or bigger collections of input material in one pass.
This has become increasingly important as users want models to analyze books, contracts, research archives, or large codebases without constantly losing earlier context.
Improving long-context behavior is not only about increasing a number. It also involves architectural and training choices that help the model stay useful as sequences get much longer.
LLMs vs Traditional Search Engines: Key Differences
| LLMs | Traditional Search Engines |
|---|---|
| Give users a direct, synthesized answer in conversational language. | Give users a ranked list of links, snippets, and search results to explore. |
| Work best when the user asks a full question or gives detailed context. | Work best when the user wants to discover sources, compare pages, or browse options. |
| Generate responses from trained knowledge, prompt context, and sometimes retrieved documents or tools. | Retrieve information from crawled, indexed, and ranked web pages. |
| Often keep the user inside the answer itself, which supports zero-click behavior. | Usually send the user outward to websites, which keeps clicks central to the experience. |
| Can feel faster for summaries, explanations, brainstorming, and follow-up questions. | Can feel stronger for research, source validation, and finding original documents. |
| May be less transparent when sources are not clearly shown with the answer. | Are more transparent because users can inspect the ranking and open the original sources directly. |
| May struggle with breaking news or changing facts unless connected to live retrieval. | Usually handle fresh information better because search indexes update continuously. |
| Reward content that is easy to cite, summarize, and synthesize into answer-ready responses. | Reward content that ranks well through keywords, relevance, backlinks, and technical SEO. |
Limitations and Challenges of Large Language Models
Here are some of the limitations of LLMs.
Hallucinations
A hallucination happens when an LLM produces information that is false, unsupported, or invented, while still presenting it in a fluent and confident style. This is one of the most important limitations of current models because strong language generation can create an illusion of reliability even when the content is wrong.
Hallucinations happen for several reasons. The model is trained to generate plausible text, not to guarantee truth in every case, and if the prompt is ambiguous or the needed information was not learned well, the model may still produce an answer that sounds complete.
Bias and Fairness Issues
Because LLMs learn from large text corpora created by human societies, they can reflect the biases, stereotypes, imbalances, and distortions found in those corpora. This creates fairness concerns in applications involving hiring, education, law, health, or any setting where output could influence people materially.
Bias in LLMs is not always obvious. Sometimes it appears in assumptions, framing, omissions, or default examples rather than in openly harmful language. That is why evaluation and mitigation remain active areas of research and deployment work.
Reasoning Limitations
LLMs can appear highly capable on many tasks, but that does not mean they reason in a fully human or consistently reliable way. They may perform well on patterns similar to what they saw in training and still fail on unfamiliar setups, adversarial prompts, or brittle logic challenges.
This is why fluency should not be mistaken for deep understanding. The output may sound polished, yet still contain hidden gaps in reasoning or factual support.
Compute and Environmental Costs
Training and serving large models can require substantial computing infrastructure, energy, and cost. Frontier systems are associated with major investments in hardware and optimization, which is one reason access to top-tier model development remains concentrated among a relatively small number of organizations.
These costs also shape the industry’s direction. They influence the push toward efficiency techniques, smaller, stronger models, specialized deployment, and better tradeoffs between capability and resource use.
Which Tool Is Best for Increasing Your Brand LLM Visibility?
If your goal is not just to track AI mentions but to actively improve how often your brand gets surfaced, cited, and discussed inside AI answers, Radarkit is the tool I would put first on the list.
Its biggest advantage is that it does more than show vanity metrics, because it prompts AI interfaces directly, tracks visibility across 50+ countries, and helps you understand where your brand is being cited, where competitors are winning, and what content gaps need to be fixed.
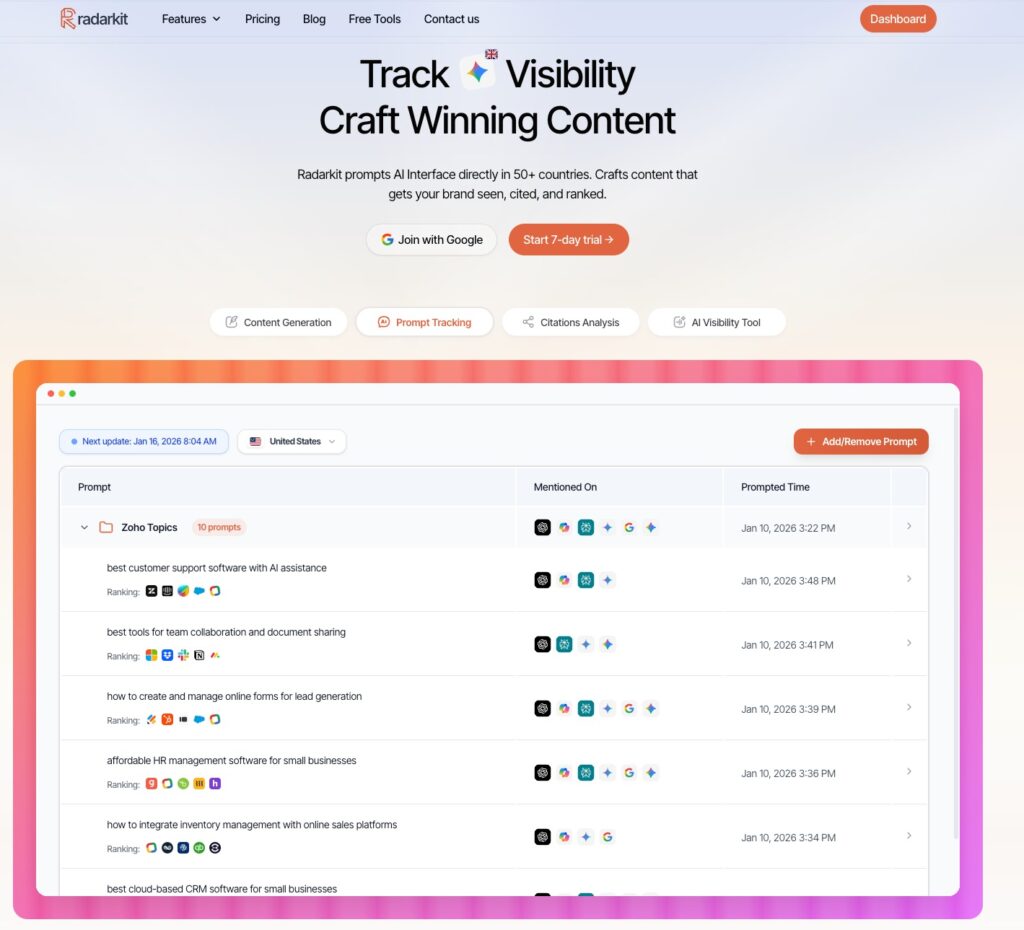
What makes Radarkit especially useful for increasing LLM visibility is that the product is built around the exact signals that matter in AI search: prompt-level visibility tracking, citation analysis, competitor comparisons, and content optimization workflows designed to help teams create pages that are more likely to be referenced by AI systems.
In practical terms, that means you are not guessing why ChatGPT, Gemini, Perplexity, or other AI systems mention one site and ignore another, because Radarkit shows the citation patterns behind those outcomes and turns them into action points.
Another reason Radarkit stands out is that it connects monitoring with execution.
The platform highlights backlink opportunities from frequently cited sites, helps teams analyze which sources AI models rely on, and includes traffic monitoring so you can connect AI visibility to real business impact instead of treating it as a disconnected reporting exercise.
That matters because increasing LLM visibility usually comes down to improving page clarity, strengthening topical authority, earning better citations, and publishing content that is easier for AI systems to trust and reuse.
Radarkit also appears to be designed for teams that want realistic market-level tracking rather than lab-style estimates.
Its official positioning emphasizes direct prompting of AI interfaces and country-level visibility checks, while third-party writeups describe it as strong for real chat-interface behavior, location-aware checks, page-level citation capture, and simple workflows that connect visibility data to optimization decisions.
That combination makes it a strong choice for agencies, content teams, and brands that want to move from “Are we visible?” to “What exactly should we change to get cited more often?”
Notable Radarkit AI Features
- AI Share of Voice: Identify exactly which sites AI Chatbots trust most for your query vs. competitors
- Location-Based Tracking: Simulate real-time queries from 40+ countries using residential proxies to catch local citations and geo-specific data
- NLP & Fact-Based Content: Create content using the specific NLP terms and entities found in most cited sources to rank in AI search engines
- 1-Click GEO Content Writer: Generates optimized content that ranks in LLMs in 5 minutes without needing Google Search Console
- Query Fanouts Tracking: Tracks how AI models break one question into multiple angles and turn them into content sections
- AI Traffic Monitoring: See which AI platforms (ChatGPT, Perplexity, Gemini, Copilot) send actual visitors to your site
How Do Local LLMs Work?
A local LLM works by running the model directly on your own computer or private server instead of sending prompts to a cloud provider.
That means the model files, inference engine, and prompt processing stay on your machine, which is why local LLMs are often chosen for privacy, control, and offline use
What Makes a Model Runnable Locally
A model becomes runnable locally when its size, memory needs, and compute demands fit the hardware you actually have available, especially your VRAM, RAM, and processor or GPU capacity.
In practice, this usually means choosing smaller models or using quantized versions of larger models so they can load into local memory and generate tokens at a usable speed.
Quantization is one of the biggest reasons local LLMs are practical today, because it compresses model weights and reduces memory usage without making the model unusable for everyday tasks.
Context length matters too, since longer prompts increase KV cache usage and raise the memory needed during inference.
Popular Local LLM Frameworks
Several frameworks make local LLMs much easier to run, and the most widely discussed ones include Ollama, llama.cpp, LM Studio, LocalAI, and vLLM.
- Ollama is popular because it simplifies downloading, managing, and serving models locally.
- llama.cpp is the lightweight inference engine that powers many local setups behind the scenes.
- LM Studio is often preferred by users who want a visual desktop interface for testing models, changing settings, and comparing outputs without dealing with too much command-line setup.
- LocalAI is useful for broader self-hosted AI stacks.
- vLLM is more suited to high-throughput, production-style deployments where performance and concurrency matter more than beginner simplicity.
When Local LLMs Are the Right Choice
Local LLMs are the right choice when privacy, control, offline access, or predictable long-term usage costs matter more than getting the absolute best cloud-model performance.
They are especially attractive for teams handling sensitive information, developers who want to self-host AI features, and users working in environments where internet connectivity is limited or unreliable.
They also make sense when you want deeper control over the stack, including which model you run, how it is configured, and where the data stays during inference.
For experimentation, internal tools, and private workflows, local models can be a very practical choice even if they are smaller than frontier cloud models.
Limitations of Local LLMs
The biggest limitation of local LLMs is hardware pressure, because model size, VRAM, RAM, and context length all place hard limits on what you can run smoothly.
If your machine is underpowered, local inference can become slow, unstable, or restricted to smaller quantized models that may not match the quality of stronger cloud systems.
Local setups also require more hands-on configuration, more awareness of model formats and runtimes, and more troubleshooting than most hosted AI tools.
So while local LLMs offer strong privacy and control benefits, they usually ask for more technical effort and often involve tradeoffs in speed, convenience, and model quality
FAQs About Large Language Models
Do LLMs actually understand language?
LLMs process language extremely well, but they do not understand it in the same way humans do. They learn patterns from very large text datasets and use those patterns to generate responses that sound meaningful and context-aware.
That is why they can explain concepts, answer questions, and follow prompts with impressive fluency. At the same time, fluent output should not be confused with human consciousness, self-awareness, or lived understanding.
How many parameters do modern LLMs have?
Modern LLMs vary widely in size, from smaller models with only a few billion parameters to frontier systems built with far larger parameter counts and much heavier compute requirements.
A parameter is one of the internal values the model adjusts during training, and the total number of parameters affects how much capacity the model has to learn patterns from data.
Still, parameter count alone does not decide which model is best. Performance also depends on training data quality, architecture, optimization, and post-training methods such as fine-tuning and alignment.
Why do LLMs hallucinate?
LLMs hallucinate because they are trained to generate plausible next tokens, not to guarantee factual truth in every answer. If a prompt is vague, the training signal is weak, or the model lacks reliable grounding for a topic, it may still produce a confident response that sounds correct but is actually wrong.
This is one reason retrieval, verification, and source grounding matter so much in high-stakes use cases. Systems that combine an LLM with external documents or live retrieval can often reduce hallucinations by giving the model stronger factual support.
Can LLMs replace human writers?
LLMs are very useful writing assistants, but they are not full replacements for human writers. They can help with drafting, summarizing, rewriting, brainstorming, and organizing ideas, which makes them valuable for speed and structure.
Human writers still matter for judgment, originality, lived perspective, emotional nuance, and final quality control. In most real publishing workflows, the strongest results come from combining AI speed with human editing and expertise.
What is the difference between GPT and Llama?
GPT is a model family associated with OpenAI, while Llama is a model family associated with Meta. Both belong to the broader category of large language models, but they differ in openness, deployment style, ecosystem, and how developers typically access them.
In practical terms, GPT models are usually accessed through OpenAI products and APIs, while Llama models are generally more flexible for direct deployment, experimentation, and customization in developer-controlled environments.
Conclusion
Large language models may look mysterious from the outside, but their core workflow is surprisingly structured: they turn text into tokens, map those tokens into numerical representations, process relationships through transformers and self-attention, and generate responses one token at a time.
What makes them powerful is the scale of their training, the efficiency of transformer architecture, and the post-training methods that help them become more useful, conversational, and task-ready.
At the same time, understanding how LLMs work also makes their limitations easier to see. They can hallucinate, reflect bias, consume significant compute, and struggle when factual grounding or domain-specific precision is weak.
That is why the most effective way to use them is not to treat them like perfect digital minds, but to understand them as powerful predictive systems that work best when paired with good prompting, verification, retrieval, and human judgment.
As LLMs continue to improve, they will become even more embedded in how people search, write, code, learn, and work with information.
Once you understand the full pipeline from training to inference, it becomes much easier to see both why these models are so impressive and why using them well still requires clarity, context, and critical thinking.

